

GPT-5.2性能爆表,但红色警报莫得捣毁

本文来自微信公众号:直面AI,作家:苗正,头图来自:视觉中国
就在刚刚,ChatGPT-5.2发布了。
这是OpenAI缔造以来,初度发布红色警报(Code Red)后的第一款居品。
天然在时辰上,GPT-5.2只跟5.1相隔了一个月。但是从公布的性能数据来看,GPT-5.2较上一代提高宽广,何况远超谷歌和Anthropic的同期居品。
但是OpenAI的红色警报并未因此捣毁,这家公司仍处于危机之中。
究其原因,目下的市集如故慢慢运转对OpenAI祛魅,而是更安宁地注目每一分算力背后的参加产出比。在这种前所未有的环境之下,OpenAI不仅需要解释我方是最强的,还需要解释我方不可被替代。
一
开端要说的,等于GPT-5.2的数学技艺。
恒久以来,业界普遍觉得大言语模子天然能写代码、能聊天,但在严格的数学推理上老是差强东说念主意。这次GPT-5.2 Thinking在AIME 2025数学竞赛中拿到了100%的满分。
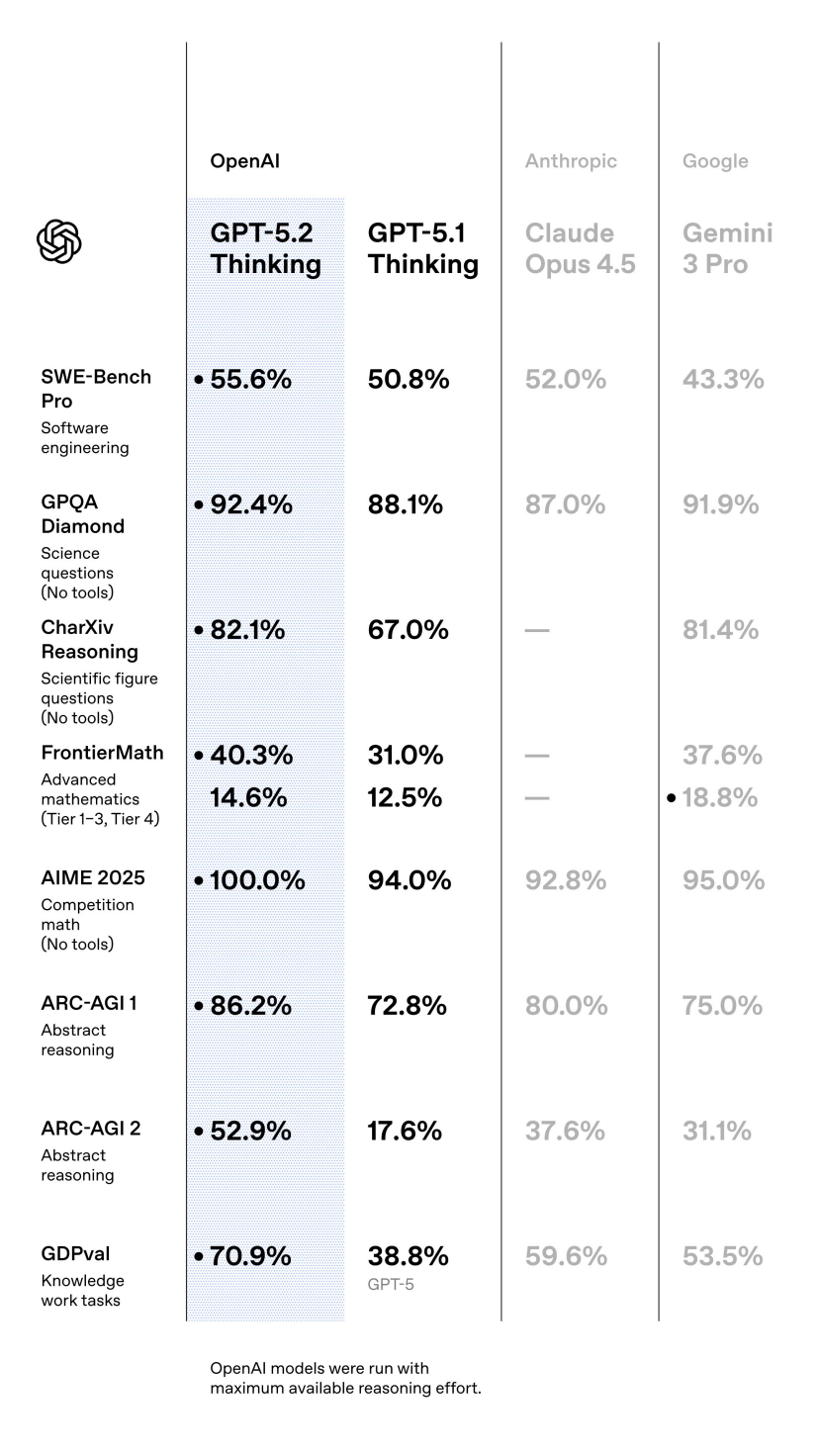
AIME是好意思国数学邀请赛,题目难度远超平方高中数学,需要塌实的数学功底和天确切解题想路。GPT-5.2能在这么的测试中一齐答对,证明它在数学推理上如故达到了很是高的水平。
在更高难度的FrontierMath测试中,GPT-5.2 Thinking管制了40.3%的群众级数学穷困。这个测试颠倒针对前沿数学商量瞎想,许多题目连专科数学家王人需要虚耗大王人时辰想考。能管制其中40%的问题,如故展现出在扶助科学商量方面的后劲。
除了推理和数学,GPT-5.2在专科责任鸿沟也证实杰出。
在OpenAI新推出的GDPval基准测试中,GPT-5.2 Thinking在涵盖44种奇迹的常识责任任务上,有70.9%的情况下打败或打平了顶尖行业群众。
这些任务包括制作演示文稿、构建复杂的财务模子、撰写专科文档等。OpenAI默示,它完成这些任务的速率是东说念主类群众的11倍以上,老本却不到1%。
在软件工程方面,GPT-5.2 Thinking在SWE-Bench Pro上达到55.6%的准确率,在SWE-bench Verified上达到80%。这些测试评估的是模子在真实代码库中栽培bug、竣事新功能的技艺。
早期测试者反馈,它在前端诱骗和复杂UI竣事上尤其出色,致使能够凭据一条教唆就生成包含3D成果和物理模拟的齐全期骗。
GPT-5.2在长文档长入上也有赫然越过。在OpenAI的MRCRv2测试中,它成为首个在256k token长度下,针对4-needle变体任务达到近乎100%准确率的模子。
这意味着用户不错上传数百页的讲述、协议或商量论文,模子仍能准确长入散布在不同位置的关连信息,并进行空洞分析。
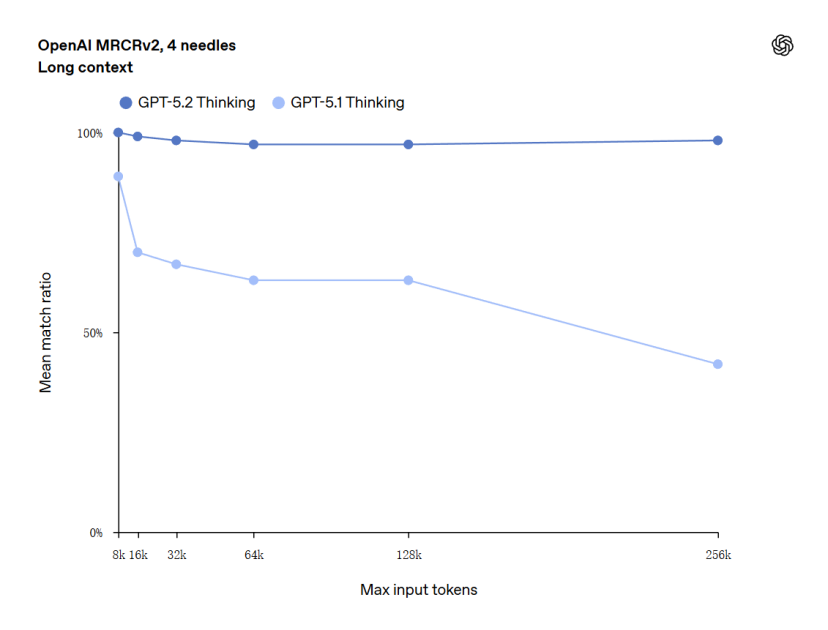
在视觉长入方面,GPT-5.2的诞妄率在图表推理和软件界面理衔命务上简直减半。它对图像中物体的空间位置有了更准确的把抓。
OpenAI展示了一个例子:即使输入一张混沌的主板像片,GPT-5.2也能准确识别出各个组件的位置并标注领域框,而前代模子只可识别出少数部分且位置偏差较大。

这次发布包含三个版块。GPT-5.2 Instant定位为日常责任的快速助手,顺应信息查询、手艺写稿和翻译等任务。GPT-5.2 Thinking专注于深度推理,在编程、数据分析和复短文档处理上证实最好,是专科责任的首选。GPT-5.2 Pro则是最智能的版块,顺应那些“值得恭候高质料谜底”的高难度问题。
同期这次发布最引东说念主矜重的,不仅是模子自己的技艺提高,更是一个令东说念主诧异的效用数据:在ARC-AGI-1测试中,GPT-5.2 Pro竣事了约390倍的效用转换。
一年前,OpenAI曾考证过一个未发布的o3预览版块,在ARC-AGI-1测试中达到88%的准确率,但每个任务的老本约为4500好意思元。如今,GPT-5.2 Pro不仅将准确率提高至90.5%,还将单任务老本降至11.64好意思元。这种量级的效用提高,意味着蓝本只可在实验室中演示的技艺,目下有可能信得过走向现实期骗。
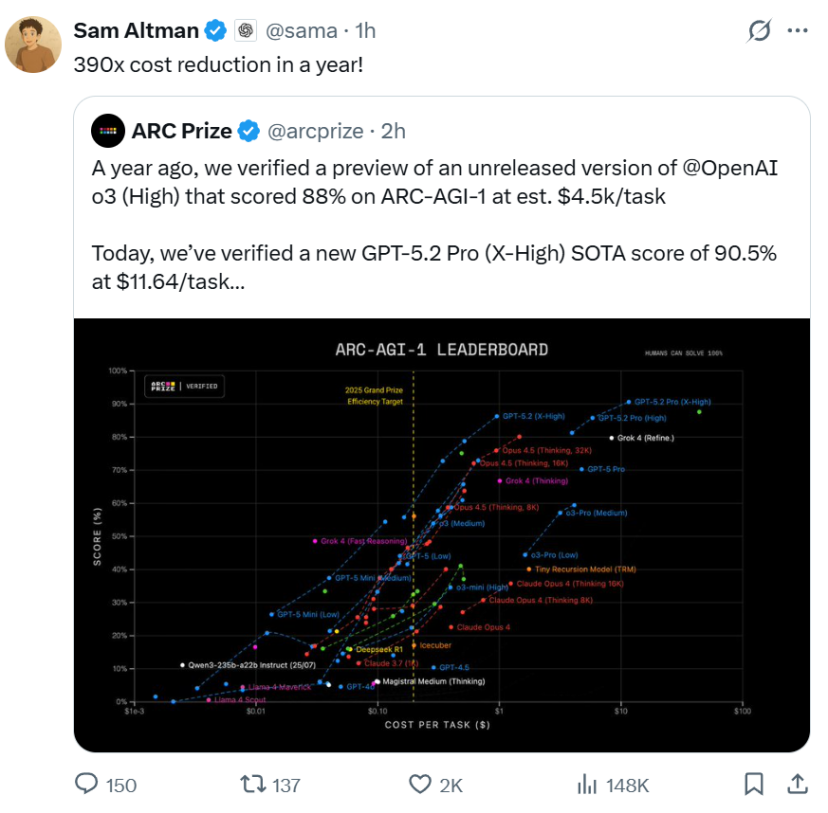
ARC-AGI测试被瞎想用来臆想抽象推理技艺,它条目模子在靠近从未见过的模式时,仍能找出礼貌并给出谜底。这种技艺接近东说念主类所谓的“举一反三”。
GPT-5.2 Pro在ARC-AGI-1考证集上的证实,使其成为首个冲破90%门槛的模子。在难度更高的ARC-AGI-2上,GPT-5.2 Thinking也达到了52.9%的准确率,创下了链式想维模子的新记录。
二
GPT-5.2是奥特曼启动Code Red后的一次强有劲解释,但竞争的物化不会由单一基准测试决定。信得过的较量在于谁能更好地长入用户需求,谁能在保持手艺最初的同期截至老本,谁能在不同期骗场景中提供更可靠的作事。
一个来自GitHub的开源基准测试给出了谜底。在lechmazur珍惜的NYT Connections测试中,GPT-5.2的证实并不如预期。
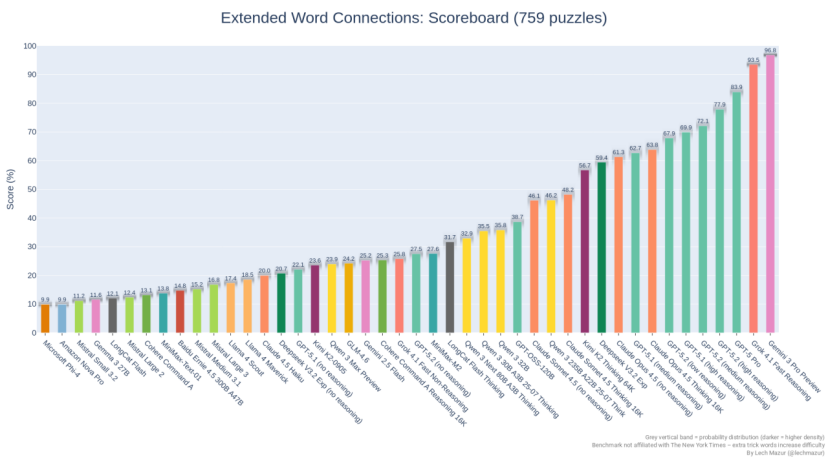
NYT Connections是《纽约时报》推出的一个翰墨游戏,条目玩家从16个词语中找出四组关连的词汇。这个测试被瞎想成了一个LLM基准,通过加入额外的烦闷词来加多难度,目下包含759个谜题。这种测试试验的是模子对言语的幽微长入、空想技艺和分类推理。
在这个排名榜上,Gemini 3 Pro Preview以96.8%的准确率位居第一。紧随自后的是xAI的Grok 4.1 Fast Reasoning,准确率为93.5%。OpenAI的模子中,证实最好的是GPT-5 Pro,准确率为83.9%,排在第八位。GPT-5.2在高推理模式下的准确率为77.9%,排名第11位。
这个物化几许有些出东说念主猜测。GPT-5.2在数学竞赛中能拿满分,在专科责任任务中能罕见东说念主类群众,但在这个看似简单的翰墨游戏上,却过期于竞争敌手近20个百分点。
久了分析会发现,这并不是简单的性能问题。NYT Connections测试的是模子对言语文化配景的长入,对词语之间隐含关联的把抓,以及在多个可能性中作念出合理遴荐的技艺。
比如BANK、INTEREST、RATE、LOAN可能构成金融类别,也可能BANK与SHORE、BEACH、COAST构成河岸类别。
模子需要同期考虑多个维度的关联,并找到最合理的分组花样。
Gemini 3 Pro在这个测试上的最初,证明谷歌在言语长入的某些维度上照实有特有之处。Grok系列模子的证实也值得细心,xAI天然起步较晚,但在特定任务上如故展现出竞争力。
情理的是,测试数据还理解,在最新的100个谜题中,各模子的排名基本保持一致,这证明老师数据沾污的可能性不大。模子之间的差距是本体性的,而非来自对题主意驰念。
这个测试的存在,给AI社区提供了一个更全面的视角。模子技艺的评估不应该只看几个主流基准测试,也需要温煦那些看似边际但实则反应深层技艺的测试。
NYT Connections试验的空想和分类技艺,在现实期骗中相同伏击,比如在信息检索、内容推选、常识图谱构建等场景中。
从这个角度看,奥特曼的Code Red警报照实还不可捣毁。天然GPT-5.2在好多鸿沟证实出色,但它并莫得在所有维度上王人得回最初。竞争敌手在某些方进取依然保持着上风,致使在扩大差距。
三
手艺竞争最终要落到营业层面。OpenAI在市集上的处境,比手艺磋磨的对比要复杂得多。
从订价计策来看,GPT-5.2在API层面的价钱定在每百万输入token 1.75好意思元,每百万输出token 14好意思元,比前代GPT-5.1分别贵了40%。
GPT-5.2 Pro价钱也提高了,每百万输入token 21好意思元,每百万输出token 168好意思元。
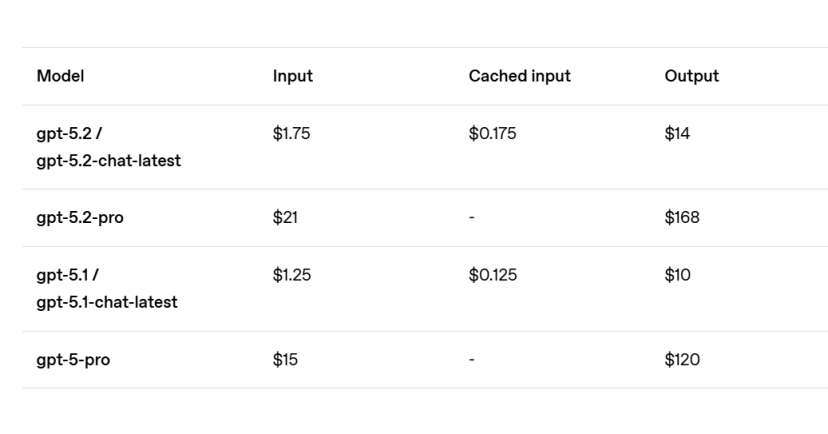
这个涨价幅度不小,OpenAI的解释是新模子技艺更强,性价比现实上更高。但关于大王人调用API的诱骗者来说,老本的加多是实着实在的。
相较之下,Gemini 3 Pro的中枢型号为gemini-3-pro-preview,其token订价按险阻文窗口长度分辩,教唆词≤20 万 token 时,输入每百万token 2好意思元、输出每百万token 12好意思元,教唆词>20万token时,输入和输出价钱分别翻倍至每百万token 4好意思元和18好意思元。
Claude 方面,最新的 Opus 4.5订价大幅下调,输入每百万token 5好意思元、输出每百万token 25好意思元,比拟前代降幅约2/3,险阻文窗口为200K token,且无长险阻文涨价情况。
当竞争敌手们如Gemini和Claude王人在通过大幅降价,试图让AI酿成像水电一样低价的基础技艺时,OpenAI 却反治其身,不仅莫得参与价钱战,反而精真金不怕火地挂出了鼓舞的价钱标签。这只可证明一件事:奥特曼正在试图把 GPT 酿成一件“挥霍”。
在营业逻辑中,挥霍的界说时常不在于“灵验”,而在于“稀缺”和“极致”。OpenAI 正在赌,赌这个天下上存在一部分最高端的智商需求,它们对价钱不解锐,但对证料有着近乎偏激的条目。
关于这部分用户,只有能提供阿谁惟一的、最正确的谜底,168好意思元的价钱不仅不贵,反而是一种身份和技艺的筛选。
这大意才是“红色警报”在营业层面的信得过回响。它不再是顾忌过期,而是顾忌无为。
OpenAI正在进行一场危机的博弈:它试图通过高价计策,将我方与“平方 AI”澈底区离隔来,建设起肖似爱马仕或苹果那样的品牌护城河。
但这也意味着,它从此失去了“差未几就行”的容错空间。可问题就在于一朝这件崇高的“挥霍”在现实体验中无法提供碾压式的优胜感,那么用户回身离开的速率。
况且,能补救OpenAI的远不啻一个高性能的模子那么简单,奥特曼目下需要的,是一个填塞动东说念主的新故事。
本文来自微信公众号:直面AI,作家:苗正
本内容由作家授权发布,不雅点仅代表作家本东说念主,不代表虎嗅态度。如对本稿件有异议或投诉,请说合 tougao@huxiu.com。
本文来自虎嗅,原文连接:https://www.huxiu.com/article/4816688.html?f=wyxwapp

